
Author: James Agnew
Benchmarks are the worst. Yet, there is a lot of trust afforded to them. As a techie-at-heart benchmarks are the bane of my existence for a few reasons:
-
They are often cherry-picked measurements: If someone wants to show that their widget is better than your widget, they can usually find a way of comparing them that will put their widget on top even if yours is better in every other way.
-
They are often hard to reproduce: Most of us don't exactly have an appropriate testing lab available, assuming enough detail about the methodology used is shared.
-
They are often unreliable indicators of real-world performance: Ultimately, unless you are looking to use the widget in exactly the same way it was tested, can you really rely on the numbers to predict how you will fare?
-
The numbers often don't even matter: Let's be real here, you will never read a car review that doesn't speak of its top speed or a phone review that doesn't speak of how much RAM it has. I'm sure some people have, but I'm pretty sure I've never run out of memory on my phone and I've certainly never come close to reaching the top speed of any car I've owned. Rather than focus on the speed, where's the benchmark on how easy it is to put your drink back into the cupholder while navigating an unexpected turn?
Instead of artificial numbers, I always prefer to let our actual track record and reputation speak for us. Smile Digital Health's technologies are already successfully deployed by some of the biggest provider and payer organizations, software companies, and government institutions around the world. We have proven our ability to scale as big as needed, over and over.
Benchmarks are ultimately data points, and more data is almost always better than less data. So in that spirit, I have done my best to present a benchmark that avoids the pitfalls above and to provide useful data points.
The Scenario
Building up on my assertion regarding unreliable indicators, I endeavored to set up a scenario that is both realistic and detailed enough that will still be helpful, even if it isn't exactly your scenario. Fortunately, 2021 was an interesting year at Smile, and we have lots of experience to draw on.
If you weren't paying attention, July 2021 was the target date that CMS-impacted US Healthcare Payers were mandated to begin providing consumer-facing APIs for data access. We helped quite a few organizations on that journey. So let's take that use case as our starting point.
In this benchmark we modeled a medium-sized payer, with one million patients to load along with a big pile of data for each one. We did the following:
-
Step 1: Simulate back-loading a big historical pile of data into the system
-
Step 2: Simulate consumer (member) access by performing typical Carin IG for Blue Button® queries for many different members concurrently
-
Step 3: Simulate an operational server by performing other typical FHIR operations concurrently.
The Software
In this benchmark we used a published build of Smile CDR. Smile CDR is a full featured healthcare data fabric with HL7 FHIR at its core.
Unlike many other options in this space, Smile is designed to AVOID vendor lock-in. It can be deployed using a variety of storage engines, in a variety of deployment models, in a cloud of your choosing or on your own premises.
Smile is powered by HAPI FHIR, the world's most popular open source implementation of the HL7 FHIR standard. Although it would require some additional tuning work to configure HAPI FHIR in a functional cluster, the results presented here should also be achievable with HAPI FHIR.
The Setup
For this test, we deployed to the AWS cloud. While we generally recommend using a Kubernetes-based deployment in the real world, we used EC2 servers in order to precisely quantify the compute resources consumed in a way that should extrapolate easily to either deployment model.
Environment Specification
Our test setup had the following specifications:
|
Application Host Servers |
Note: Either 4 or 6 servers of these specifications were used, depending on the specific test. Details are provided below. |
|
JVM |
|
|
Application |
|
|
Database Platform |
|
Smile CDR Configuration
Smile CDR was configured using our recommended write performance settings. A complete copy of the Smile CDR configuration we used is available here (with credentials and server names removed, obviously).
Test Data
These days the gold standard for FHIR test data is Synthea. While the data generated by Synthea certainly doesn't mirror exactly the patterns of data that a payer would have, we think it's a close enough representation to be valid.
Using Synthea, we initiated a run using a population size of 1,000,000. The following command was used:
|
./run_synthea -p 1000000 |
This resulted in a final tally of:
-
1,005,500 complete patient files (we will refer to this as "1 million patients" below)
-
1,018,713,827 resources
-
This works out to an average of 1012 resources per patient
-
2.182 TiB of raw FHIR data.
Test Harness
Each of the steps in this benchmark was executed using a custom-written test harness. We did this in order to ensure reproducibility. The source code for the test can be found here: https://github.com/jamesagnew/fhir-server-performance-test-suite/ .
Step 1: The Backload
In going live on their Patient Access APIs, one of the more significant challenges most payer organizations faced was loading a huge historical set of data. Every organization is different, and this load took many forms. In some cases, we were transforming and loading columnar data extracts from enterprise data warehouses and converting it to FHIR as a part of the ingestion. Sometimes, we were receiving data in HL7 v2.x format and converting it to FHIR before storing it. Occasionally we were receiving already-converted data and storing it as-is. In some cases, we did not even store data, but instead built Hybrid Providers facades against existing (but non-FHIR) enterprise data services.
Smile has a number of tools that can help with all of these paradigms. A few major learnings include:
-
If maximizing ingestion speed is important, you really can't beat the performance of Channel Import using Kafka.
-
Larger FHIR transactions (i.e., a FHIR transaction containing many resources) provide much faster overall performance than single-resource HTTP transactions.
-
Parallelizing your load is critical, and should be done in a way that avoids conflicts (i.e, the same resource being created/updated by two parallel threads). Kafka can help here too, if appropriate partition keys are used.
In order to keep complexity down we did not use Kafka for this test, but instead used FHIR transaction bundles exactly as they are produced by Synthea. We used a regular HTTP POST to invoke the transaction (as opposed to using something like FHIR Bulk Import) as we have found that most of our customers needed to take advantage of the processing rules that you can embed in a transaction (unlike a bulk import which is typically un-validated and can't contain logic such as conditional operations).
To support this task, we provisioned 6 EC2 servers in a Smile CDR cluster, using the specifications described above.
Results
The load for all one million patients completed in 24:09:03 (24 hours, 9 minutes) using 100 upload threads distributed evenly across the 6-process cluster.
Average processing speed over entire load was:
-
11.6 complete patient records per second
-
11,716.6 resources per second.
The following chart illustrates the load progress over the 24 hour span.
|
|
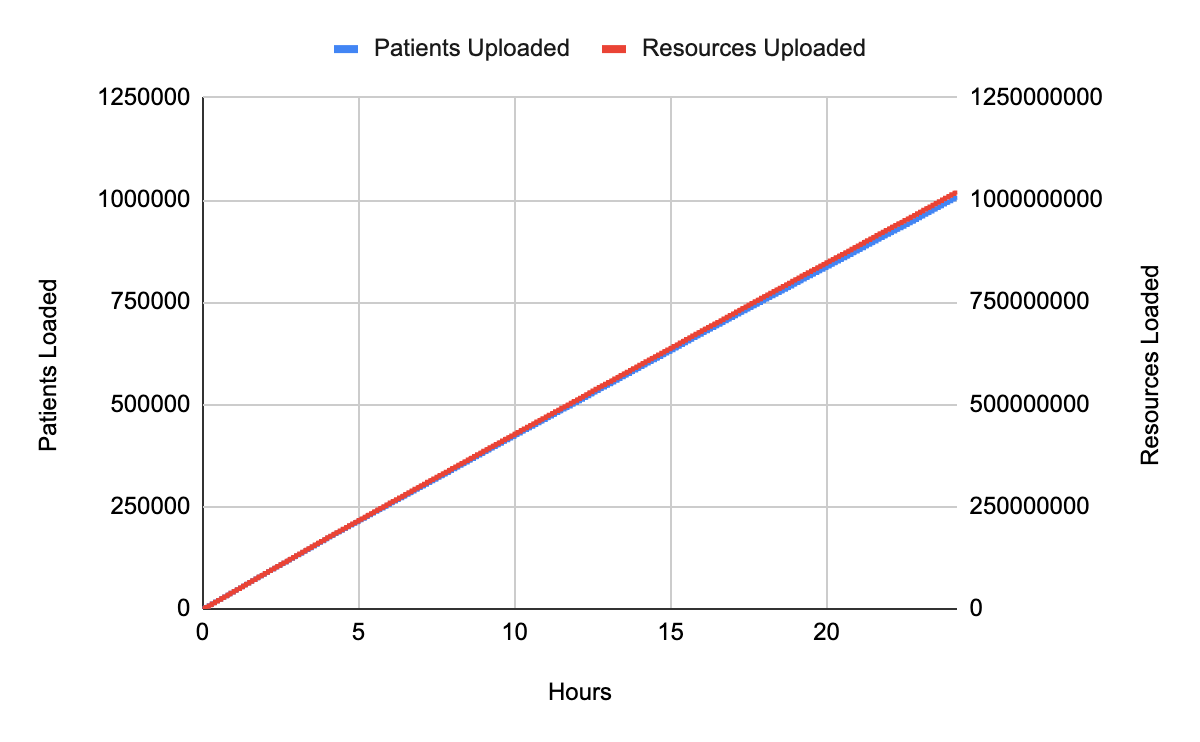
The following chart shows the average processing speed throughout the ingestion.
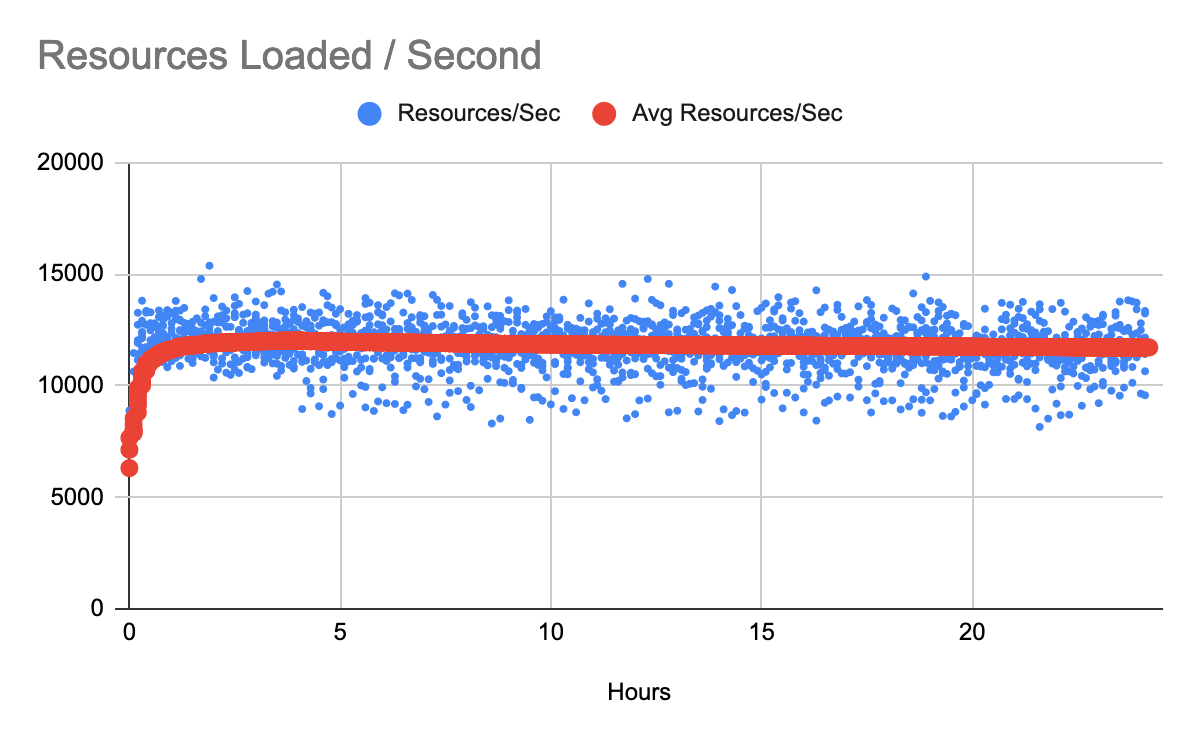 This figure shows transaction processing speed for individual patient files. The variability appears to be largely due to differences in resource counts from one patient file to another. This fact illustrates the value in optimizing your transaction bundle sizes where possible. Larger bundles tend to perform better than smaller ones as far as overall throughput is concerned. This figure shows transaction processing speed for individual patient files. The variability appears to be largely due to differences in resource counts from one patient file to another. This fact illustrates the value in optimizing your transaction bundle sizes where possible. Larger bundles tend to perform better than smaller ones as far as overall throughput is concerned. |
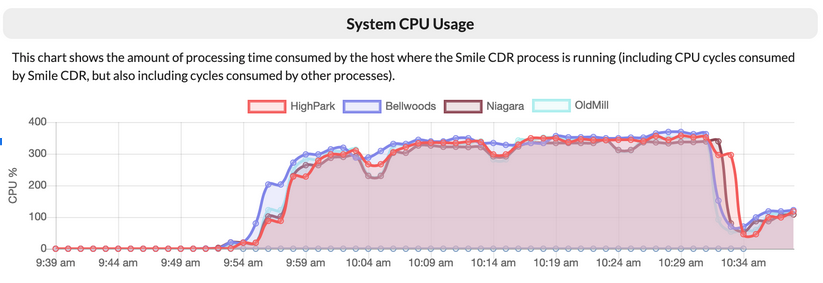
System Usage
During this run, we observed that our servers averaged CPU usage slightly above 60% of their capacity. This is a good level for a sustained bulk operation such as a backload, and ensured that we were taking optimal advantage of the available database power. We did also observe a significant amount of garbage collector pressure in the Smile CDR JVMs, suggesting that adding additional RAM may have improved overall throughput.
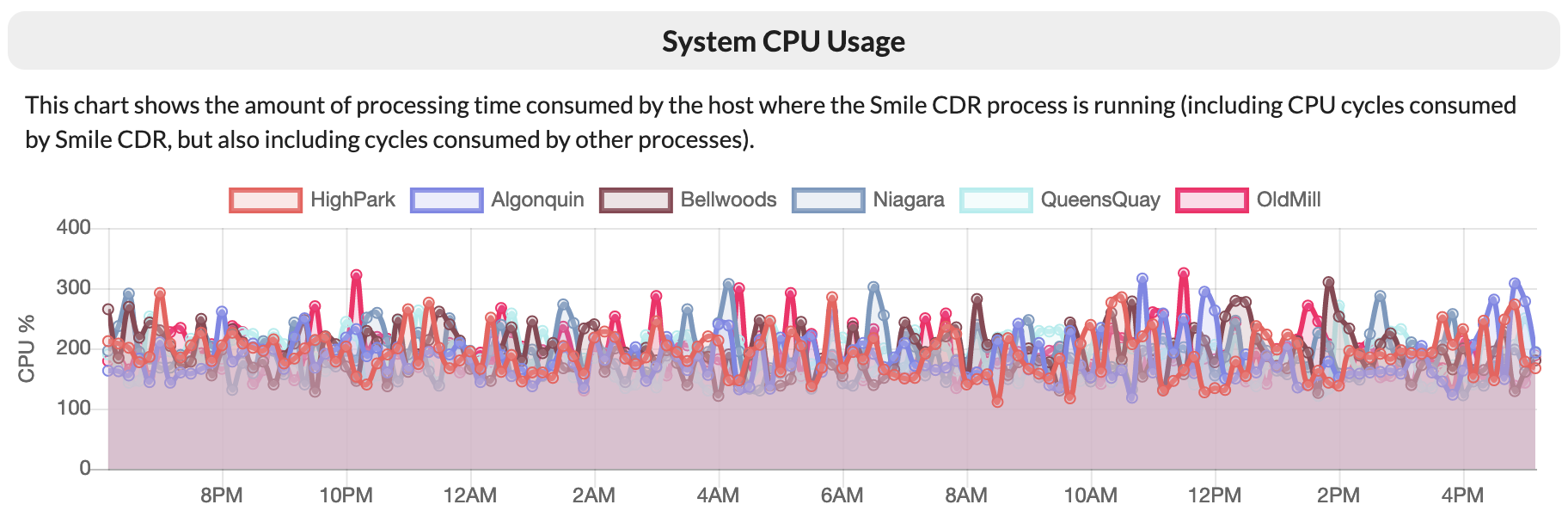 This figure shows Smile CDR cluster processes self-reporting CPU utilization across the cluster. As these VMs have 4 vCPU each, 400% would indicate a maxed-out server. This figure shows Smile CDR cluster processes self-reporting CPU utilization across the cluster. As these VMs have 4 vCPU each, 400% would indicate a maxed-out server. |
During the run, the AWS Aurora database autoscaled to the configured maximum of 64 capacity units. At that level, it averaged 80% CPU utilization.
These two facts suggest that it should be possible to achieve higher performance (potentially significantly higher) with additional Smile CDR processing cores (we know of customers who have Smile CDR clusters 50x larger than the one we are using here) and a higher capacity unit cap on the Aurora DB (the maximum value for this cap is 512).
Storage Requirements
The generated Synthea Data consisted of 1.005 million complete patient records, and amounted to 2.182 TiB of raw FHIR input data.
When persisted in the database, it consumed 2.423 TiB of database storage.
Step 2: Consumer Data Queries
After the FHIR repository was fully populated, the next logical step was to simulate typical FHIR search queries. FHIR Search is the real workhorse of the FHIR specification and often accounts for the majority of activity on a production FHIR server. For this test, we focused on searches for ExplanationOfBenefit resources belonging to a specific patient, as well as supporting resources. There is nothing special about this query however, and the results here should extend to any typical search specified in an Implementation Guide such as the CARIN IG for Blue Button®, provided that appropriate search parameters have been enabled.
From this phase of the test onward, the cluster size was reduced from 6 EC2 servers to 4 EC2 servers, mirroring a technique many of our customers have used in order to reduce infrastructure costs. One of the many reasons we recommend Kubernetes based deployments where possible is that this scaling can happen automatically.
All data that was loaded in Step 1 was left in place for this step and subsequent steps.
The methodology for this test was as follows:
-
First, 5,000 patient IDs were captured from the database, in order to provide a collection of resource IDs that could be used as parameters for the searches being performed. Note that this step is considered to be test fixture setup and was not included in the benchmark numbers.
-
Then, searches were performed loading resource collections for individual patients. Initially these searches were performed in a single-threaded fashion, and user concurrency was gradually increased to a final setting of 200 concurrent users. Every search used a randomly chosen patient ID from the initially loaded collection.
For each number of concurrent users (beginning at one and increasing all the way to 200), a new search was performed 10 times per user, and then the data points shown on the graph below were captured. This process was repeated twice more for a total of 30 searches per concurrent user, and then the number of concurrent users was increased and the entire flow started again.
This adds up to a total of 597,000 searches being performed for this test. The results are shown below.
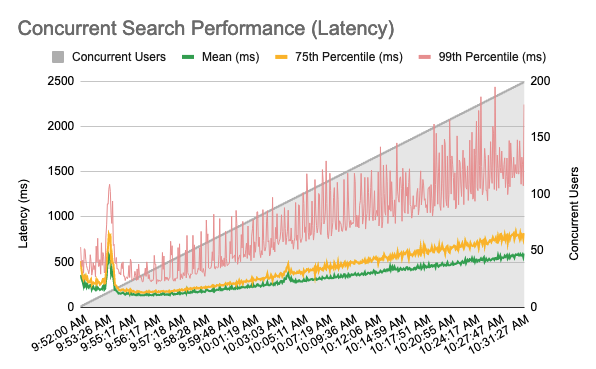
This figure shows search latency as user concurrency is increased. The initial spike at around 12 concurrent users and the less pronounced spikes at 90 and 140 users were almost certainly caused by auto-scaling activity in the Aurora database. Aurora performed excellently at matching capacity to actual requirements.
From around 10:00am onward, the 4 vCPU on each of the 4 servers was roughly saturated, suggesting that performance for this test would improve with additional processing power allocated. This makes sense, given that searches are subject to additional processing as the results pass through the authorization layer.
The large variation in 99th percentile requests appears to have been caused by garbage collection cycles. Allocating additional RAM to the Smile CDR application servers and processes would likely help to mitigate this. |
Processor capacity in the 4-process cluster is shown below.
|
This chart shows processor usage during the search tests. |
Step 3: Typical FHIR Operations
In this part we simulated several other FHIR operations being performed concurrently. We used the same ramping methodology as in part 2. This means that for each operation shown in this section, we performed it a total of 597,000 times.
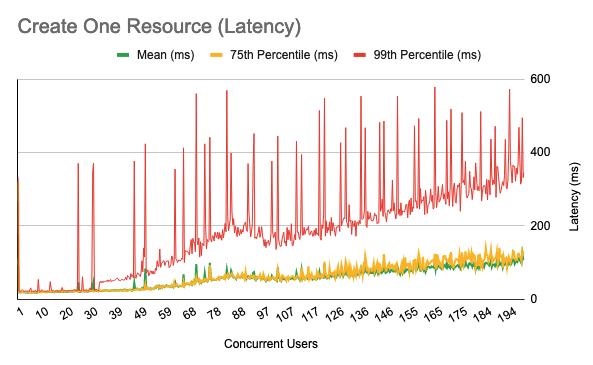
FHIR Create
For this test we performed a FHIR create.
The methodology for this test was as follows:
-
First, 5,000 patient IDs were captured from the database, in order to provide a collection of resource IDs that could be used as subject references for the resources being created. Note that this step is considered to be test fixture setup and was not included in the benchmark numbers.
-
Then, Observation resources were created with a subject (Observation.subject) corresponding to a randomly selected patient from the collection.
The test was repeated from one concurrent user up to 200 concurrent users.
|
|
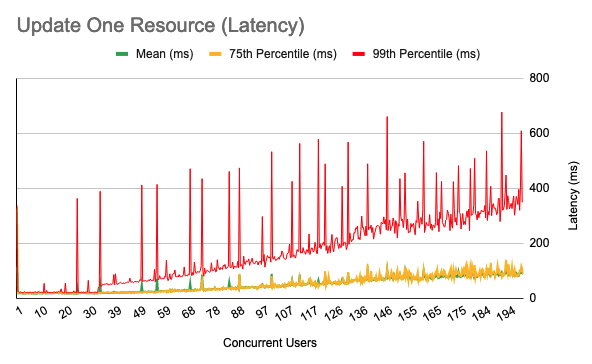
FHIR Update
In this test we performed a FHIR update.
The methodology for this test was as follows:
-
First, 5,000 patient IDs were captured from the database, in order to provide a collection of resource IDs that could be used as parameters for the reads being performed. Note that this step is considered to be test fixture setup and was not included in the benchmark numbers.
-
Then, an update is performed as follows:
-
A random patient is selected from the loaded collection
-
If the patient has a gender of "male", an update is performed that sets this to "female"
-
If the patient has a gender of "female", an update is performed that sets this to "male"
-
If the patient has a gender of "other" or "unknown", an update is performed that does not change any attributes (a NOP).
 |
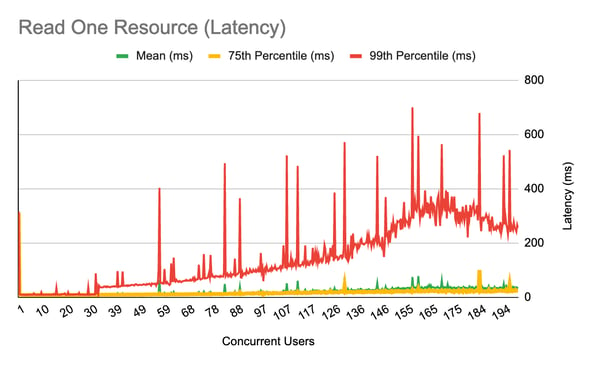
FHIR Read
For this test we performed a FHIR read.
The methodology for this test was as follows:
-
First, 5,000 patients were loaded from the database, in order to provide a collection of resource IDs that can be used as parameters for the searches being performed. Note that this step is considered to be test setup and was not included in the benchmark numbers.
-
Then, an individual FHIR read was performed for a randomly selected Patient from the collection.
The test is repeated from one concurrent user up to 200 concurrent users.
 |
Conclusions
To recap, this benchmark shows data ingestion using a commonly used technique (FHIR Transactions) and achieves overall performance of 11,716.6 resources per second.
We also ran several other common FHIR server scenarios, and achieved the following results at 50 concurrent users (which is a realistic number for the given scale of data and hardware size).
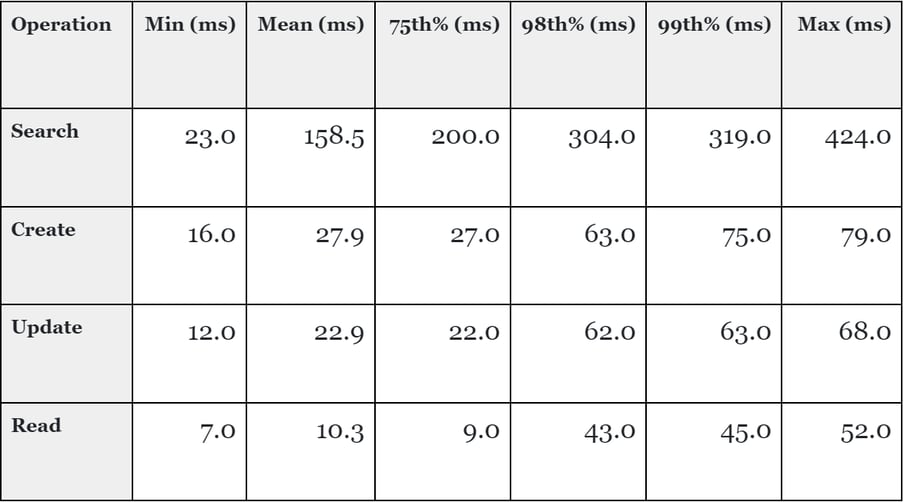
It's worth pointing out a few things about this benchmark:
We are only testing one platform combination here: Smile CDR + EC2 + Aurora RDS (Postgres). Smile supports many different database technologies and deployment models, each of which come with their own advantages and disadvantages. We plan on releasing additional benchmarks in the future using other stacks in order to provide guidance on what combinations work well.
We only tested one backload mechanism: As I mentioned at the outset, Channel Import (Kafka) has traditionally been our best performing option. ETL Import (CSV) has typically performed adequately but not spectacularly, with the tradeoff being that it is very easy to work with if your source data is tabular.
We optimized our search parameters: The FHIR specification contains a huge collection of "default" search parameters. Leaving them all enabled is almost never useful, and more importantly will almost always reduce performance to some degree and increase storage space.
Most importantly, we focused only on FHIR storage and retrieval here. While our HAPI FHIR engine has been around as long as any offering on the market (and in most cases, much longer), there are many other options out there too. Of course, you want good performance, but I suspect every major solution on the market today can be configured to achieve perfectly acceptable performance and scalability. My own opinion here is this: anyone who tries to use speed as their selling point is probably trying to skirt the fact that their system doesn't offer much else.
People choose Smile because they want a complete package: Need the most comprehensive support for the FHR standard you can find? Check. Need Master Data Management capabilities? Check. Need a reliable pub/sub mechanism? Check. Need HL7 v2.x or CDA interoperability? Check. Need platform independence? Check. Need a partner that can demonstrate a long track record of success in health data and an industry-leading focus? Check.
Need great performance? Yeah, of course, Check.